日本の製造、物流、建設、介護、モビリティの現場でAI導入が進む一方、実務で最も大きな壁になっているのが「学習データ不足」です。カメラを設置しても十分な枚数が集まらない。異常や事故はめったに起きない。個人が写り込むため社外共有できない。ラベル付けに人手がかかりすぎる。こうした問題が、現場AIの実装を止めています。
そこで注目されているのが、**合成データ(Synthetic Data)**です。
合成データとは、実際に撮影・収集したデータそのものではなく、シミュレーション、数理モデル、3D環境、生成AI、統計モデルなどによって作られた人工的なデータのことです。画像認識AIであれば、人物、機械、荷物、フォークリフト、床面、照明、影、カメラ角度、異常姿勢などを仮想空間で再現し、同時にバウンディングボックス、セグメンテーションマスク、深度情報、姿勢情報などの教師ラベルも自動生成できます。
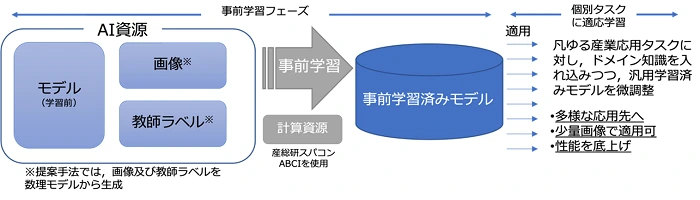
産総研は、実画像を一切使わず、数式から自動生成した大規模画像データセットを用いて画像認識モデルを構築する手法を開発し、大量の実画像、プライバシー確保、人手によるラベル付けコストといった商業利用上の課題を解消できる可能性を示しています。さらにNEDOと産総研は、画像識別だけでなく画像領域分割にも対象を広げ、産業応用で必要な学習精度を底上げするモデル構築に取り組んでいます。
なぜ日本の現場AIに合成データが必要なのか
日本の現場AIは、海外の大規模データ中心のAI開発とは少し事情が違います。工場、倉庫、建設現場、介護施設、店舗、港湾、農場などでは、AIに使えるデータが簡単には集まりません。
理由は大きく分けて、次の4つです。
- 撮影コストが高い
現場ごとにカメラ設置、照明調整、撮影許可、作業者説明、データ保存、ラベル付けが必要になります。 - プライバシー制約が強い
作業者、来店客、患者、入居者、ドライバーなど人が写るデータは、匿名化や利用目的の整理が欠かせません。 - レア事故がほとんど撮れない
転倒、接触、挟まれ、衝突、荷崩れ、誤進入などは安全上「起きてほしくない」事象であり、実データとして集めるのが難しい領域です。 - 現場差分が大きい
同じ工場でも、ライン、照明、床材、作業服、機械配置、カメラ角度、時間帯が変わると、AIの認識性能が落ちることがあります。
合成データは、この不足を「撮る」のではなく「作る」ことで埋める技術です。特に現場AIでは、実データだけでは足りない異常姿勢、死角、夜間、雨天、粉じん、逆光、作業者の重なり、荷物の遮蔽、機械との接近などを意図的に生成できる点が重要です。
合成データは“データ拡張”ではなく“安全検証のインフラ”になる
従来のデータ拡張は、既存画像を回転させる、明るさを変える、ノイズを加えるといった処理が中心でした。これに対して、合成データは「まだ現場で撮れていない状況」を最初から設計できます。
たとえば、倉庫内のフォークリフト接触リスクを検知するAIを作る場合、実際に危険な接近シーンを何千回も撮影することはできません。しかし仮想空間であれば、次のような条件を安全に再現できます。
- フォークリフトと作業者の距離が近い
- 荷物で作業者の半身が隠れている
- 夜間照明で影が強い
- パレットが斜めに置かれている
- 作業者がしゃがんでいる
- カメラが天井、壁面、車載のいずれかにある
- ヘルメットや安全ベストの色が異なる
- 床面に反射や汚れがある
NVIDIAは、Omniverse Replicator for Isaac Sim を使って、自律移動ロボットがフォークリフトを検出して事故を避けるためのDNN学習に9万枚以上の合成画像を生成した例を紹介しています。同社は、Replicatorが開発者の設定した分布に基づくデータ生成、コーナーケースやテストケースの生成、品質監査のためのツール・パラメータ追跡を支援すると説明しています。
このように、合成データは単なる「学習枚数の水増し」ではありません。むしろ、レア事故や危険シナリオを再現し、安全検証を前倒しするためのインフラになりつつあります。
製造現場:外観検査と異常検知を“希少不良”から解放する
製造業でAI導入が進みやすい領域の一つが、外観検査です。傷、汚れ、欠け、印字不良、異物混入、塗装ムラ、溶接不良などをAIで検出する取り組みは広がっています。しかし、現場でよく起きる課題は「正常品は大量にあるが、不良品が少ない」ことです。
不良率が低い工場ほど、AIに必要な不良画像が集まりません。しかも、不良の種類によっては、意図的に発生させると材料やライン時間を無駄にします。合成データを使えば、良品の3Dモデルや少数の実画像をもとに、傷の位置、深さ、角度、反射、照明条件、背景を変えた不良パターンを生成できます。
現場で有効な合成データの使い方は、次のようなものです。
- 正常品に微細な傷や欠けを付与する
- 照明、反射、影、カメラ角度を変える
- 部品の向きや重なりをランダム化する
- ラベル付きの不良領域を自動生成する
- 実データで不足している不良カテゴリを補う
- 新製品立ち上げ前に検査AIの初期モデルを作る
特に少量多品種の日本の製造現場では、製品ごとに大量撮影してAIを作る方法は限界があります。合成データは、ライン立ち上げ前、試作品段階、量産初期からAI検査を準備できる点で大きな意味を持ちます。
物流・倉庫:フォークリフト、AMR、荷崩れを仮想空間で検証する
物流現場では、自律移動ロボット(AMR)、AGV、フォークリフト、コンベヤ、ピッキング作業者が同じ空間で動くケースが増えています。ここで重要になるのは、AIが「人」「荷物」「パレット」「台車」「フォークリフト」「危険な接近」を正しく認識できることです。
しかし、実際の倉庫で危険な接近や接触事故を大量に集めることはできません。合成データを使えば、事故に近い状況を仮想環境で再現できます。
- 作業者が棚の影から出てくる
- パレットで人が半分隠れる
- フォークリフトの爪が荷物に隠れる
- AMRの前に台車が横切る
- 荷崩れ直前の姿勢を再現する
- 低照度、逆光、反射床を再現する
- カメラ汚れやブレを加える
NVIDIAは Omniverse Replicator について、物理的に正確な3D合成データを大規模に生成し、バウンディングボックス、深度、法線、セマンティックラベルなどのアノテーションを出力できる仕組みとして説明しています。倉庫シーンのような複雑な環境では、実写だけで網羅できないパターンを合成で増やせる点が重要です。
建設・インフラ:転倒、接触、危険区域侵入を安全に再現する
建設現場やインフラ保守では、AIカメラを使った安全管理が期待されています。たとえば、転倒検知、ヘルメット着用確認、危険区域への侵入検知、重機と作業者の接近検知、夜間作業の異常検知などです。
ただし、建設現場のAIはデータ収集が難しい分野です。現場ごとに足場、重機、照明、天候、作業服、動線が違い、同じ条件を再現しにくいからです。さらに、転倒や接触事故は実際には起こしてはいけないため、学習データとして集めることが困難です。
合成データを使えば、以下のような安全検証シナリオを作れます。
- 作業者が段差でつまずく
- 重機の死角に人が入る
- 荷下ろし中に作業者が接近する
- 夜間照明で人物が見えにくい
- 雨、粉じん、逆光でカメラ映像が劣化する
- ヘルメットや安全ベストの色が変わる
- 危険区域の境界線が資材で隠れる
建設AIで重要なのは、事故を予測することだけではありません。「この角度のカメラでは人が隠れる」「この照明条件ではヘルメットを誤検出する」といった弱点を事前に発見することです。合成データは、AIモデルだけでなく、カメラ配置や安全ルールそのものを検証するためにも使えます。
介護・医療周辺:プライバシーを守りながら転倒検知を鍛える
介護施設や医療周辺の現場では、転倒検知、徘徊検知、離床検知、見守りAIへの期待が高まっています。しかし、この分野はプライバシー制約が特に強い領域です。居室、病室、浴室、トイレ周辺などは、カメラ映像の利用に慎重な設計が求められます。
合成データは、実在する入居者や患者の映像を大量に共有せず、姿勢、動線、転倒パターン、照明条件を再現できる可能性があります。
たとえば、以下のようなケースです。
- ベッドから立ち上がる
- 歩行中にふらつく
- 車椅子から移乗する
- 夜間に暗い廊下を歩く
- カーテンや家具で体の一部が隠れる
- 転倒後に床に倒れた姿勢になる
ただし、合成データだからといって自動的にプライバシーリスクが消えるわけではありません。欧州データ保護監督機関(EDPS)は、合成データについて、結果が実際の個人データに該当しないかを確認するプライバシー保証評価が必要だと説明しています。また、合成データは大量のラベル付き学習データを必要とする機械学習に役立つ一方、データ保護の観点では評価が不可欠です。
合成データは“匿名データ”ではない:プライバシー評価が必須
合成データ活用で最も誤解されやすいのは、「合成だから個人情報ではない」と考えてしまうことです。これは危険です。
実データをもとに生成した合成データの場合、生成方法によっては元データの特徴が残りすぎる可能性があります。特に、少数グループ、珍しい属性、特徴的な行動履歴、希少疾患、特殊な作業パターンなどは、再識別や属性推定のリスクにつながる場合があります。
NISTは、差分プライバシーを満たす合成データについて、元データと同じスキーマや相関を維持しながら、元データに含まれる個人に対して証明可能なプライバシー保証を提供できると説明しています。一方で、すべての合成データ生成手法が差分プライバシーや何らかのプライバシー特性を満たすわけではないとも明記しています。
つまり、現場AIで合成データを使う際は、次の整理が必要です。
- 実データから生成したのか、完全なシミュレーションから生成したのか
- 元データに個人情報や機密情報が含まれるか
- 生成データから元の個人や企業が推測される可能性があるか
- 差分プライバシーなどの技術的保証があるか
- 合成データの利用範囲、共有範囲、保存期間を決めているか
- 実データとの近さとプライバシー保護のバランスを評価しているか
NISTは、合成データの品質を評価する SDNist も公開しており、合成データセットの有用性とプライバシーを比較し、品質レポートを生成するためのツールとして説明しています。合成データは「作れば終わり」ではなく、実データに対する忠実度、有用性、プライバシーの三点で評価することが重要です。
現場AI向け:合成データ導入テンプレート
合成データを現場AIに導入する際は、いきなり3Dシミュレーターや生成AIツールを選ぶのではなく、次の順番で設計するのが現実的です。
ユースケースを一つに絞る
最初から「工場全体をAI化する」「倉庫全体を自動化する」と考えると失敗しやすくなります。まずは、検出対象と業務判断が明確なテーマに絞ります。
- フォークリフトと作業者の接近検知
- 倉庫内の転倒検知
- 部品の傷検査
- ヘルメット未着用検知
- 危険区域侵入検知
- 荷崩れ予兆検知
- 介護施設の離床・転倒検知
実データで不足している条件を洗い出す
合成データは、実データの代替ではなく補完として使うのが基本です。まず、実データに何が足りないかを明確にします。
- 夜間映像が少ない
- 雨天・粉じん・逆光が少ない
- 転倒や接触のデータがない
- 作業服やヘルメットのバリエーションが少ない
- カメラ角度が固定されすぎている
- 異常品・不良品のサンプルが少ない
- 人物が遮蔽されるケースが足りない
シナリオ仕様書を作る
合成データの品質は、生成モデルよりも「何を再現するか」の設計で大きく変わります。現場担当者、情シス、AI開発者、安全管理者が一緒にシナリオ仕様書を作るべきです。
- 検出したい対象
- 事故・異常の定義
- カメラ位置
- 照明条件
- 背景・床・設備
- 人物姿勢
- 物体の配置
- 遮蔽条件
- 天候・時間帯
- 正常ケースと異常ケースの比率
教師ラベルを自動生成する
合成データの大きな利点は、画像だけでなく教師ラベルも同時に作れることです。画像認識AIでは、次のようなラベルが重要になります。
- 物体カテゴリ
- バウンディングボックス
- セグメンテーションマスク
- 姿勢情報
- 深度情報
- 距離情報
- 危険区域との位置関係
- 接触・非接触の状態
- 時系列イベントラベル
実写データでは人手でラベル付けする必要がありますが、合成データでは仮想空間上の物体情報からラベルを自動出力できます。これにより、AI開発で大きな負担となるアノテーション工数を削減できます。
実データで必ず検証する
合成データで学習したAIは、必ず実データで検証する必要があります。仮想空間で高精度でも、現場映像では床の反射、カメラノイズ、作業者の動き、機械の汚れ、照明のちらつきなどで精度が落ちることがあります。
検証時に見るべきポイントは次の通りです。
- 実映像での検出率
- 誤検知の種類
- 見逃しの種類
- 現場ごとの差分
- 時間帯ごとの差分
- カメラごとの差分
- 合成データを足した場合の改善幅
- 合成データが逆に精度を下げていないか
合成データ活用の成否は、「どれだけリアルに作ったか」だけでは決まりません。実データで検証し、足りない条件を再生成するサイクルを回せるかどうかが重要です。
部門別に見る合成データの活用ポイント
製造部門
外観検査、不良検知、作業姿勢検知、設備異常検知で有効です。特に、不良品が少ない、撮影条件が変わりやすい、ラベル付けが難しい現場では、合成データによって初期モデルの立ち上げを早められます。
物流部門
倉庫内の人・フォークリフト・AMR・荷物の位置関係を再現し、接触リスクや危険動線を学習できます。レア事故を実際に起こさず、安全検証に必要なシーンを増やせる点が強みです。
建設・インフラ部門
転倒、重機接近、危険区域侵入、ヘルメット未着用、夜間作業、悪天候などのシナリオを再現できます。現場ごとに環境差が大きいため、現場写真やBIM/CADデータと組み合わせた合成データ生成が有効になります。
介護・医療周辺部門
転倒検知、離床検知、見守りAIの検証に使えます。ただし、実在人物のデータを元に合成する場合は、プライバシー評価、利用目的、共有範囲、保存期間を明確にする必要があります。
情報システム・AI推進部門
合成データの管理基盤、データカタログ、モデル評価、アクセス制御、ログ管理を整備する役割を担います。経済産業省の AI事業者ガイドライン では、AI事業者向けに本編、概要、チェックリスト、ワークシートが公開されており、社内AIガバナンスを作る際の参照資料として使えます。
合成データ導入時に確認すべきチェックリスト
合成データは便利ですが、導入すれば自動的にAI精度が上がるわけではありません。現場導入前には、次のチェックが必要です。
- 合成データで補いたい不足条件が明確か
- 実データと合成データの役割分担を決めているか
- 生成したシナリオが現場の実態と合っているか
- レア事故や危険ケースの定義が安全管理部門と一致しているか
- 教師ラベルの形式がAI学習パイプラインと合っているか
- 実データでの検証セットを別に確保しているか
- 合成データだけで性能評価を完結させていないか
- 生成元データに個人情報や機密情報が含まれていないか
- 合成データのプライバシーリスクを評価しているか
- データ生成条件、ツール、バージョン、乱数シードを記録しているか
- モデル改善後に、どの合成データが効いたのかを追跡できるか
特に重要なのは、生成条件の記録です。どの背景、どの照明、どの姿勢、どの異常パターンで作ったデータがAIの精度改善に効いたのかを追跡できなければ、合成データは再現性のない“使い捨てデータ”になってしまいます。
調達時にベンダーへ聞くべき質問
合成データツールやAI開発ベンダーを選ぶ際は、デモ画像の見栄えだけで判断してはいけません。現場AIでは、生成品質、ラベル品質、評価方法、プライバシー、再現性が重要です。
- どの種類の合成データを生成できるか
- RGB画像、深度、セグメンテーション、姿勢、時系列イベントを出力できるか
- 自社のCAD、BIM、3Dモデル、現場写真を利用できるか
- 照明、天候、カメラ角度、遮蔽、反射を制御できるか
- レア事故や危険シナリオを定義して生成できるか
- 教師ラベルの精度をどう検証しているか
- 実データとのドメインギャップをどう評価するか
- 生成条件とデータバージョンを記録できるか
- 合成データに個人情報や機密情報が残らない設計か
- 差分プライバシーや匿名化評価に対応できるか
- モデル精度改善に効いたデータを分析できるか
- 現場ごとの再学習・再生成サイクルを支援できるか
合成データの導入は、単なるAI開発の外注ではありません。現場の安全設計、品質管理、データガバナンスを含むプロジェクトとして扱う必要があります。
まとめ
合成データは、日本の現場AIにとって重要な加速装置になりつつあります。なぜなら、製造、物流、建設、介護、モビリティの現場では、AIに必要なデータを実写だけで集めることが難しいからです。
特に効果が大きいのは、次のような領域です。
- 不良品や異常品が少ない外観検査
- 転倒や接触など実際には起こしたくない安全検証
- 人が写るため共有しにくい介護・医療周辺データ
- 倉庫や建設現場のように環境差が大きい画像認識
- カメラ角度、照明、遮蔽、天候のバリエーションが必要な現場AI
ただし、合成データは万能ではありません。実データとのギャップ、ラベル品質、プライバシーリスク、生成条件の再現性を管理しなければ、AIの誤検知や過信につながります。
これからの現場AIでは、「データを集められるまで待つ」のではなく、「必要な条件を設計し、生成し、実データで検証する」流れが主流になります。
学習データ不足を、現場撮影だけでなく“生成”で埋める。合成データは、日本の現場AIをPoC止まりから実運用へ進めるための、重要なデータインフラになっていくはずです。


、SpaceXにxAIを統合")


